Introduction
This article evaluates deep reinforcement learning algorithms on simulated problems of constrained discrete and online resource allocation in project management. The study examines whether appropriately configured reinforcement learning agents can outperform classic constrained optimization approaches in stochastic environments.
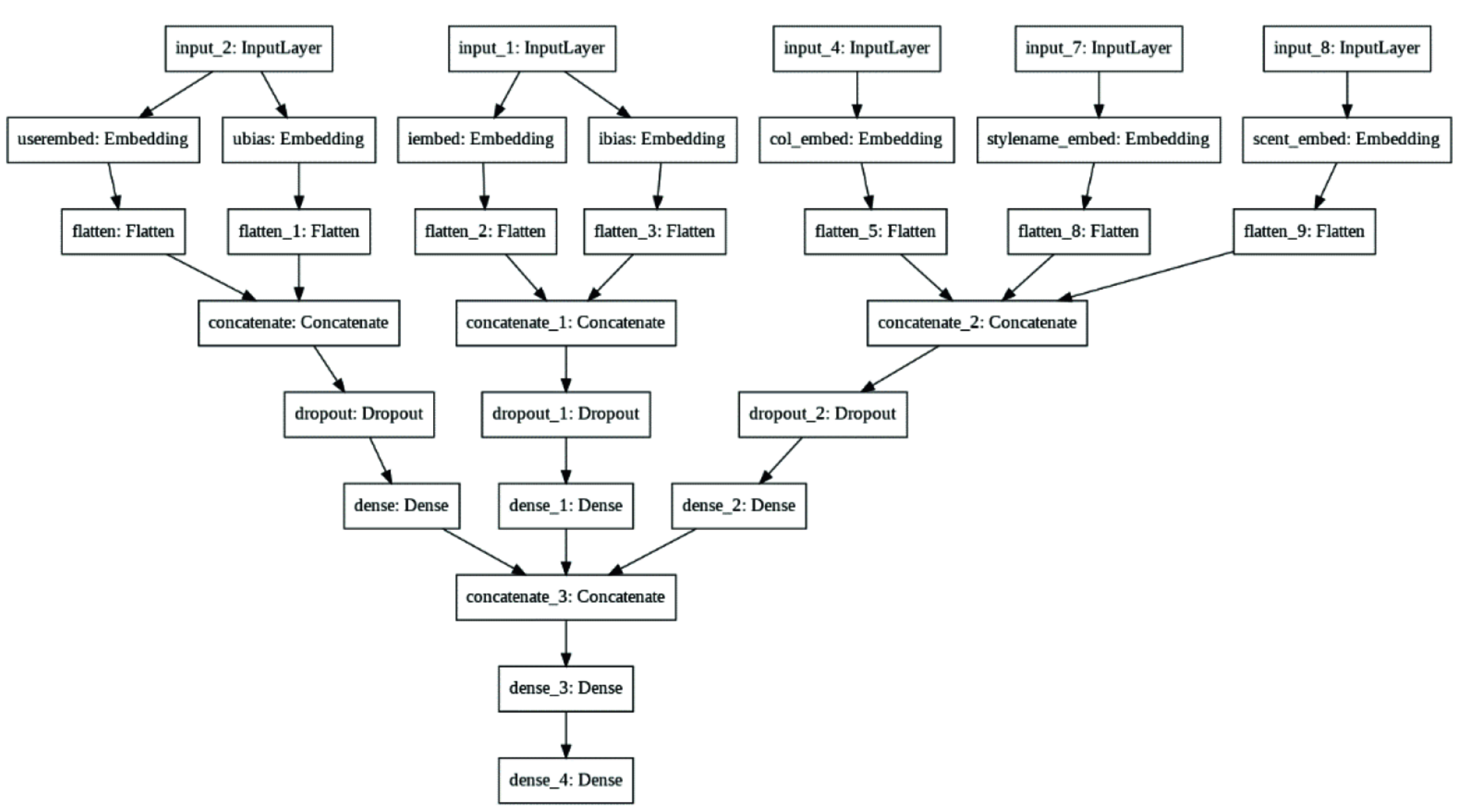
 RL resource allocation agent overview
RL resource allocation agent overview
Publication and Citation
Publication: Business Informatics. Informatyka Ekonomiczna, Volume 1, Issue 63, Pages 56-74, 2022
Author: Filip Wójcik
Institution: Wrocław University of Economics and Business
DOI: 10.15611/ie.2022.1.05
Access: Available through Business Informatics journal
Citation: Wójcik, F. (2022). Utilization of Deep Reinforcement Learning for Discrete Resource Allocation Problem in Project Management – A Simulation Experiment. Business Informatics. Informatyka Ekonomiczna, 1(63), 56-74. https://doi.org/10.15611/ie.2022.1.05
Research Overview
The paper presents a simulation experiment comparing deep reinforcement learning algorithms against traditional optimization methods for resource allocation in project management. The research hypothesis posits that a carefully chosen RL-based agent can outperform classic constrained-optimization approaches in simulated environments with varying levels of uncertainty.
Theoretical Foundation
Project Management Context
Project management encompasses the application of knowledge, skills, tools, and techniques to project activities to meet project requirements. Work on each project is divided into several phases: conceptualization, definition, planning, execution, and termination. Optimal planning, including estimation, scheduling, and constrained allocation, has been extensively researched because project activities are subject to precedence, resource, and time constraints on limited resources.
Reinforcement Learning Framework
The research employs reinforcement learning, a subfield of machine learning focused on autonomous agents interacting with environments. Agents receive rewards by randomly acting in the environment, gradually improving performance. The goal is to learn actions that maximize expected cumulative reward over time.
The study formalizes reinforcement learning problems using Markov Decision Processes (MDP):
- State space describing the environment
- Action space of possible interventions
- Transition dynamics describing consequences
- Reward signals for feedback
- Policy optimization for maximum returns
Methodology
Simulator Design
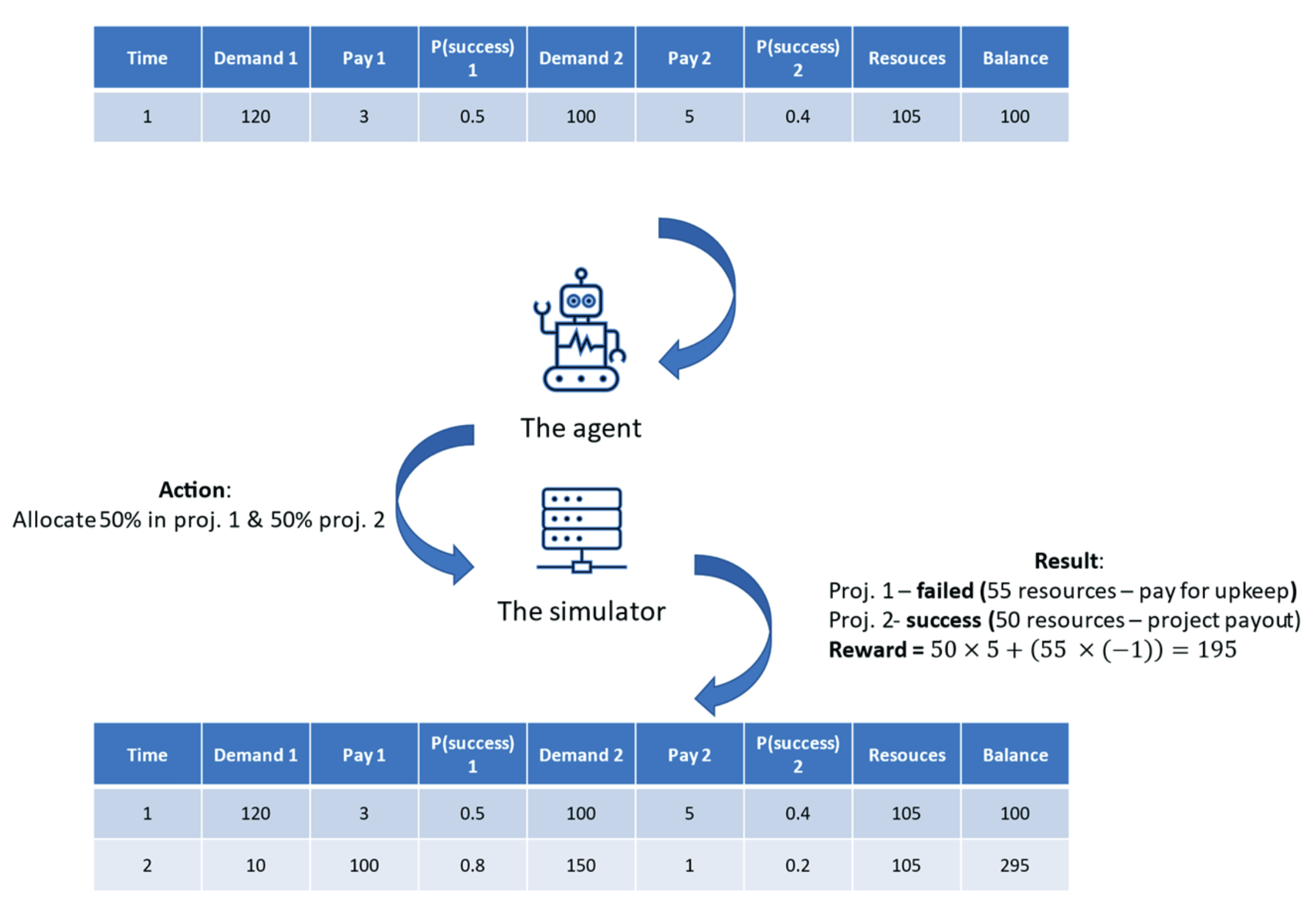
A dedicated simulator was designed to assess RL applicability in resource allocation for project management. The simulator represents an analogy to constrained human resource allocation tasks for companies across subsequent time periods.
Observation Space Components
- Balance of simulated company at each timestep
- Number of available resources
- Upkeep costs for idle resources
- Resource increase costs for expansion
- Project success probabilities
- Rewards per resource allocated
- Maximum demand for resources in projects
Action Space
The discrete control setting allows agents to choose from:
- Allocate demand for project 1
- Allocate demand for project 2
- Split allocation between both projects
- Keep resources idle
- Reduce resources by 10/25/50%
- Increase resources by 10/25/50%
Experimental Design
Three simulation environments were created with different difficulty levels:
Easy Environment
- Success probability: 70% average (μ = 0.7, σ = 0.2)
- High chance of project success
- Agents can generate large incomes without risking bankruptcy
Moderate Environment
- Success probability: 50% average (μ = 0.5, σ = 0.2)
- Balanced risk-reward scenario
- Agents must choose projects wisely and potentially split allocations
Hard Environment
- Success probability: 30% average (μ = 0.3, σ = 0.2)
- Challenging conditions with frequent failures
- Difficult to generate income and avoid early termination
Algorithms Tested
Five different agent types were evaluated:
- Random Agent: Baseline selecting random actions
- Optimization Agent: Classic constraint optimization performing greedy expected reward maximization
- VPG Agent: Vanilla Policy Gradient with GAE calculation
- A2C Agent: Advantage Actor-Critic with N-step GAE estimation
- PPO Agent: Proximal Policy Optimization with clipped surrogate objective
Statistical Validation
The testing procedure consisted of:
- 500 independent random simulations before training
- 300 training iterations for RL agents
- 500 independent test simulations
- Welch ANOVA testing at α = 0.01 significance level
- Games-Howell post-hoc pairwise comparisons
Key Findings
Easy Environment
- Optimization agent achieved the best performance: 5400.996 mean score
- PPO second: 5221.025 mean score
- AC and VPG similar: ~4685 mean scores
- All significantly outperformed the random baseline
Moderate Environment
- PPO achieved 3145.002 mean score
- Optimization: 1696.866 mean score
- VPG and AC: ~1500-1650 mean scores
- PPO showed 85% improvement over optimization
Hard Environment
- PPO achieved positive returns: 529.445 mean score
- AC showed slight positive performance: 137.743 mean score
- Optimization had negative returns: -115.573 mean score
- VPG also negative: -73.364 mean score
Statistical Significance
All pairwise comparisons showed statistically significant differences (p « 0.001) with large effect sizes. The PPO agent demonstrated:
- Consistent performance in challenging environments
- Robustness across difficulty levels
- Ability to maintain positive returns when traditional methods failed
Technical Implementation
Neural Network Architecture
Both actor and critic networks utilized:
- Input layer processing state vectors
- Multiple dense layers with 128 neurons
- Hyperbolic tangent activation for internal layers
- Softmax output for action selection (actor)
- Linear output for value estimation (critic)
Training Parameters
- Learning rate optimization for each algorithm
- Discount factor γ for future rewards
- Advantage estimation with smoothing parameter λ
- Clipping parameter 0.2 for PPO stability
Practical Implications
When to Use Optimization
Classic optimization remains optimal for:
- Stable, well-defined environments
- High success probability scenarios
- Single-step greedy decisions
- Deterministic outcomes
When to Use Reinforcement Learning
PPO and advanced RL methods excel in:
- Challenging, stochastic environments
- High uncertainty conditions
- Long-term planning requirements
- Sequential decision problems
Research Contributions
This study makes the following contributions:
- Application of RL to project management sequential resource allocation
- Comparative evaluation with statistical validation across multiple difficulty levels
- Practical guidelines for algorithm selection based on environment characteristics
- Simulation framework reusable for future research
Limitations and Future Work
Current Limitations
The simulation represents a simplified model with:
- Discrete action space instead of continuous control
- Limited to two simultaneous projects
- Simplified resource dynamics
- No resource-locking for long-term projects
Future Research Directions
Potential extensions include:
- Continuous control formulation for exact resource allocation
- Resource-locking mechanisms for multi-period projects
- Non-deterministic project shutdowns
- Sudden resource outages
- Changing market conditions
- Multi-agent scenarios
Practical Applications
The research findings have direct applications in:
- Human resource allocation across projects
- Budget distribution in portfolio management
- Computing resource scheduling
- Supply chain optimization
- Production planning under uncertainty
Conclusion
This simulation experiment shows that deep reinforcement learning, particularly the PPO algorithm, can outperform classic optimization methods in challenging, stochastic resource allocation scenarios. While deterministic optimization remains the best choice for stable, well-defined environments, advanced RL methods are better suited for conditions characterized by uncertainty and sequential decision-making requirements.
The implementation of the simulator provides a foundation for more sophisticated designs incorporating additional real-world complexities. The results indicate that RL is a promising set of tools for complex, stochastic, multi-stage decision problems with additional information sources.