](/en/post/ml-finanace/portfolio-optimization/featured_hudaa6440116b6a8bce68e7f5f68804d86_179663_1800x310_fit_q75_h2_lanczos.webp)
Intro
Portfolio optimization is a critical tool for modern investors willing to maximize their capital utilization in the market and expected returns.
Many portfolio optimization techniques are based on different variants of constrained quadratic programming formalizations, taking as inputs expected asset returns, forms of risk metrics (like covariance matrices), and transaction costs. Next, the goal is selected (typically a maximization of return while keeping the risk level constant or minimizing the risk with varying returns ). The problem is solved either via a closed-form equation or a gradient-minimizing approach. Additional elements or steps can be included, like periodical rebalancing, the inclusion of transaction costs, or different cost functions (Sharpe ratio or similar).
This blog post will show you how to prepare and perform a simple portfolio optimization process on selected stocks. Two approaches will be utilized - purely mathematical formulation of the optimization problem and PyPorfolioOpt library that automates most of the process.
After reading this article, you will know the following:
- Key terms like portfolio, portfolio weights, and Markovitz model.
- How to prepare stock price data for portfolio optimization task using yfinance library.
- How to formulate the problem in terms of the optimization task.
- How to solve the optimization problem using the library cvxpy and dedicated PyPortfolioOpt.
The executable notebook for this article can ba found on my Github
Portfolio
The first important thing is to define what a portfolio is. In layperson’s terms, the portfolio is a set of different assets (stocks, bonds, etc. - in general: different financial instruments) (Luenberger, 1997). Typically investors seek diversification of capital, so they want to have various types of assets.
Portfolio optimization is finding optimal asset weights so that the portfolio return (final return after some investment period) is maximized in terms of the selected function.
Financial time series
Data prep
The portfolio optimization process starts with stock prices. You need to download historical prices for a specific period and instruments you are interested in. For this purpose, we will utilize a yahoo finance (yf) library, an unofficial tool for downloading prices from Yahoo! Finance
|
|
| Adj Close | Close | High | Low | Open | Volume | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AAPL | GOOG | MSFT | AAPL | GOOG | MSFT | AAPL | GOOG | MSFT | AAPL | GOOG | MSFT | AAPL | GOOG | MSFT | AAPL | GOOG | MSFT | |
| Date | ||||||||||||||||||
| 2020-01-02 | 73.562 | 68.368 | 156.592 | 75.088 | 68.368 | 160.62 | 75.150 | 68.407 | 160.73 | 73.798 | 67.077 | 158.33 | 74.060 | 67.077 | 158.78 | 135480400 | 28132000 | 22622100 |
| 2020-01-03 | 72.846 | 68.033 | 154.642 | 74.357 | 68.033 | 158.62 | 75.145 | 68.625 | 159.95 | 74.125 | 67.277 | 158.06 | 74.287 | 67.393 | 158.32 | 146322800 | 23728000 | 21116200 |
| 2020-01-06 | 73.427 | 69.711 | 155.042 | 74.950 | 69.711 | 159.03 | 74.990 | 69.825 | 159.10 | 73.188 | 67.500 | 156.51 | 73.448 | 67.500 | 157.08 | 118387200 | 34646000 | 20813700 |
For the sake of this exercise, we will utilize only “Close” prices for each asset.
|
|
| AAPL | GOOG | MSFT | |
|---|---|---|---|
| Date | |||
| 2020-01-02 | 75.088 | 68.368 | 160.62 |
| 2020-01-03 | 74.357 | 68.033 | 158.62 |
| 2020-01-06 | 74.950 | 69.711 | 159.03 |
Now we have a matrix of real numbers of shape T x A,
where T - is the number of time steps and A is the number of assets in the portfolio.
Returns
Raw prices cannot be used for portfolio optimization. One needs to calculate the returns - price changes. There are two main forms of returns calculation (Dees & Sidier, 2019):
- Gross returns - the price at time t, divided by the price at time t-1. $$ \begin{align} R_t &\doteq \frac{p_t}{p_{t-1}} \in \mathbb{R} \tag{1a} \\\ \end{align} $$
- Simple returns - percentage change of price between t-1 and t. $$ \begin{align} r_t &\doteq \frac{p_t - p_{t-1}}{p_{t-1}} = \frac{p_t}{p_{t-1}} - 1 = R_t - 1 \in \mathbb{R} & \tag{1b} \\\ \end{align} $$
- Log returns - a log of simple returns used to avoid computational underflows.
$$\begin{align}
p_t &\doteq \ln(R_t) \in \mathbb{R} & \tag{1c} \\\
\end{align}
$$
Here we will utilize simple returns
(1a), as they are easily interpretable
|
|
| AAPL | GOOG | MSFT | |
|---|---|---|---|
| Date | |||
| 2020-01-02 | 0.022816 | 0.022700 | 0.018516 |
| 2020-01-03 | -0.009722 | -0.004907 | -0.012452 |
| 2020-01-06 | 0.007968 | 0.024657 | 0.002585 |
Portfolio optimization
Porttfolio weights
In this context, a portfolio is defined as a set of asset weights vector such that (Kolm et al., 2014):
$$ \begin{align} \bf{\omega} = \left[\omega_1, \omega_2, \dots, \omega_A \right]^T,\quad \sum_{i=1}^A \omega_i = 1 \tag{2} \end{align} $$
where each $\omega_i$ is a weight of the i-th asset in the portfolio.
One might have, e.g., 20% of Apple stocks, 40% of Google Stocks, and 40% of Microsoft stocks. Therefore [0.2, 0.4, 0.2] is a set of portfolio weights.
Annualized, average asset returns (mean returns multiplied by trading days), weighted by $\omega$, constitute the portfolio returns. Formally:
$$\mu ^T \bf{\omega}$$
Theoretical foundation
The portfolio Mean-Variance optimization problem can be defined as a constrained linear model as follows (Capinski Marek & Zastawniak Tomasz, 2011; Kennedy, 2016; Kolm et al., 2014):
- The formulation as maximization problem: maximize portfolio returns while keeping variance below maximal level $\sigma_{max}^2$
$$\begin{align} &\max_{\omega \in \Omega} \omega^T\mu & \tag{3a} \\\ &\text{Subject to:} \\\ && \omega^T \Sigma \omega \le \sigma^2_{max} \\\ && \sum \omega = 1 \end{align} $$
- The formulation as minimization problem: minimize portfolio variance while achieving at least minimal desired portfolio returns $R_min$: $$\begin{align} & \min_{\omega \in \Omega} \omega^T \Sigma \omega & \tag{3b} \\\ & \text{Subject to:} \\\ && \omega^T\mu \ge R_{min} \\\ && \sum \omega = 1 \end{align} $$
Where $\mu = \begin{bmatrix}\mu_1 \\\ \mu_2 \\\ \dots \\\ \mu_A\end{bmatrix}, \forall_i \mu_i \in \mathbb{E}[r_i]$ is a vector of annualized (multiplied by trading days, usually 252) expected securities return and $\Omega$ is a universe of all possible portfolio weights combinations. $\Sigma$ is the annualized (multiplied by trading days, usually 252) asset returns covariance matrix, where $\sigma_i$ is the standard deviation of returns $r_i$ (Capinski Marek & Zastawniak Tomasz, 2011; Kolm et al., 2014):
$$ \Sigma = \begin{bmatrix} \sigma_{1,1} & \sigma_{2,1} & \dots & \sigma_{A,1}\\\ \sigma_{1,2} & \sigma_{2,2} & \dots & \sigma_{A,2}\\\ \vdots & \vdots & \ddots & \vdots\\\ \sigma_{1,T} & \sigma_{2,T} & \dots & \sigma_{A,T}\\\ \end{bmatrix} $$
“Vanilla” model extensions
One of the typically used modifications to the baseline model is the “risk aversion” parameter, defining the degree to which the investor is willing to balance the risk level with expected returns (Wilmott, 2007). With this aversion parameter, the model is formalized as the following optimization problem (Dees & Sidier, 2019; Kolm et al., 2014):
$$\begin{align} &\max_{\omega \in \Omega} \omega^T\mu - \alpha \omega^T\Sigma\omega & \tag{4a} \\\ &\text{Subject to:} \\\ && \omega \ge 0 \\\ && \sum \omega = 1 \end{align} $$
Additionally, several objective functions can be selected as the optimization goal. One of the most interpretable ones is the utilization of the Sharpe Ratio (Sharpe, 1966, 1994), defined as the reward-to-variability ratio. Formally (Dees & Sidier, 2019; Goetzmann et al., 2014):
$$ \begin{align} SR = \frac{\mu - R_f}{\sigma_p} \tag{4b} \end{align} $$
Where $\mu$ is expected assets returns (as defined above), $R_f$ is the risk-free rate (often set to zero or defined as the returns from the safest financial instrument on the market - e.g. state-issued bonds), and $\sigma_p$ is a standard deviation of portfolio returns $\sqrt{\omega^T \Sigma \omega}$. When used as the objective function in the Markowitz model, the optimization problem is formalized (Dees & Sidier, 2019; Wilmott, 2007):
$$\begin{align} &\max_{\omega \in \Omega} \frac{\omega^T\mu}{\sqrt{\omega^T \Sigma \omega}} & \tag{4c} \\\ &\text{Subject to:} \\\ && \omega \ge 0 \\\ && \sum \omega = 1 \end{align} $$
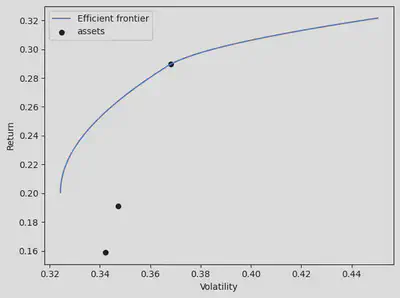
Efficient frontier
Different weights produce different portfolios varied in terms of returns and variance. An analyst can plot these portfolios on a chart where the x-axis represents variance, and the y-axis represents returns.
Portfolios are considered “efficient” if they (Stoilova 2020; Luenberger 1997):
- For a given return (point on the y-axis), offer the lowest possible variance;
- For a given variance (point on the x-axis) offer the highest possible returns.
Therefore efficient frontier is the line connecting the outermost points on the chart.
 |
|---|
| Wikipedia |
{kind=link}
Python code
Vanilla opt.-CVXPY
Let’s try to port the “vanilla Markowitz” equations (3b) - risk minimization given expected return, directly to the Python code.
$$\begin{align} & \min_{\omega \in \Omega} \omega^T \Sigma \omega & \tag{3b} \\\ & \text{Subject to:} \\\ && \omega^T\mu \ge R_{min} \\\ && \sum \omega = 1 \end{align} $$
For this purpose, we will utilize the CVXPY optimization library - a powerful tool for solving linear programming and constraint optimization problems.
Link to documentation and tutorials.
|
|
[0.59 0.285 0.125]
Let’s check the total portfolio return by calculating a dot-product between weights and annualized mean returns:
|
|
0.24
Risk aversion-CVXPY
Let’s try to implement directly in CVXPY equation (4b) - maximization of returns with risk aversion.
$$\begin{align} &\max_{\omega \in \Omega} \omega^T\mu - \alpha \omega^T\Sigma\omega & \tag{4a} \\\ &\text{Subject to:} \\\ && \omega \ge 0 \\\ && \sum \omega = 1 \end{align} $$
Let’s try to solve it for $\alpha = 0.2$
|
|
[1. 0. 0.]
It seems that the portfolio that maximizes returns, given the risk-aversion parameter, consists solely of Apple.
PyPortfolioOpt
Python library PyPortfolioOpt automates most of the operations we have done above. It contains additional features like:
- Multiple risk calculations in the form of a plug-in function - an analyst can choose from a simple covariance matrix or more advanced calculations.
- Multiple target functions - including maximization of returns given some acceptable risk, minimization of risk given desired return, Sharpe ratio, etc.
- Automatic option to validate portfolio in-sample (using “training data,” on which optimization was done).
Let’s try to replicate the calculations from CVXPY.
PyPf-the vanilla opt.
|
|
OrderedDict([('AAPL', 0.58994), ('GOOG', 0.2849), ('MSFT', 0.12516)])
The function to measure portfolio performance will give us:
- Total portfolio returns
- Volatility
- Sharpe ratio
Let’s check:
|
|
(0.24, 0.33336887072236937, 0.6599296434705707)
Portfolio return is aligned with our manual calculations from pure optimization approach.
PyPf - risk aversion scenario
|
|
OrderedDict([('AAPL', 1.0), ('GOOG', 0.0), ('MSFT', 0.0)])
Again - results are aligned with manual calculation from CVXPY.
Efficient frontier code
The library PyPorfolioOpt can produce Efficient Frontier plots as well. Once the target function has been selected, one can see different efficient frontier visualizations with possible asset configurations placed on the risk-reward scale.
|
|
Summary
Here is a brief summary of what topics were covered in this post:
- A portfolio is a set of assets/financial instruments that hold some value;
- These assets can have different weights, contributing to the total reward by the end of the period;
- The process of finding optimal weights (concerning some constraints and objectives - below) is called portfolio optimization;
- As the name suggests - this process (in its basic form) is a constrained linear programming problem;
- One of the best-known tools for solving such problems is called the “Markovitz model”, which either:
- minimizes risk for predefined minimal return;
- maximizes return while trying to keep the risk below the maximally accepted level;
- Various portfolio compositions can be plotted using efficient frontier - on the risk-reward scale;
- Such problems can be solved in Python either:
- using optimization libraries like CVXPY;
- Using specialized libraries for portfolio optimization, like PyPortfolioOpt.
Bibliography
- Capinski Marek, & Zastawniak Tomasz. (2011). Mathematics for Finance. Springer London.
- Dees, B. S., & Sidier, G. (2019). Reinforcement Learning for Portfolio Management. https://doi.org/10.48550/arxiv.1909.09571
- Goetzmann, W. N., Brown, S. J., Gruber, M. J., & Elton, E. J. (2014). Modern portfolio theory and investment analysis. John Wiley & Sons, 237.
- Kennedy, D. (2016). Stochastic financial models. CRC Press.
- Kolm, P. N., Tütüncü, R., & Fabozzi, F. J. (2014). 60 Years of portfolio optimization: Practical challenges and current trends. European Journal of Operational Research, 234(2). https://doi.org/10.1016/j.ejor.2013.10.060
- Luenberger, D. G. (1997). Investment science. Oxford Univ. Press.
- Sharpe, W. F. (1966). Mutual fund performance. The Journal of Business, 39(1), 119–138.
- Sharpe, W. F. (1994). The Sharpe Ratio, the journal of Portfolio Management. Stanfold University, Fall.
- Stoilov, T., Stoilova, K., & Vladimirov, M. (2020). Analytical overview and applications of modified black-litterman model for portfolio optimization. Cybernetics and Information Technologies, 20(2). https://doi.org/10.2478/cait-2020-0014
- Wilmott, P. (2007). Paul Wilmott introduces quantitative finance. John Wiley & Sons.