](/pl/post/rozne/chat_gpt_klamie/featured_hu7d7039dc2360cb510933ce39c4144e0b_115664_1800x310_fit_q75_h2_lanczos.webp)
Wstęp
Wyobraźnię wielu osób rozbudza w ostatnim czasie ChatGPT: cudowne dzieło firmy OpenAI, demonstrujące niesamowite umiejętności rozumienia języka naturalnego i przetwarzania informacji. Internet co chwila obiegają wieści, o zaskakujących i błyskotliwych odpowiedziach, a także o zdolnościach pisania kodu.
Jednocześnie słyszy się też o błędach popełnionych przez ChatGPT, konstruowanych “fałszywych oskarżeniach” pod adresem różnych osób (przykład sprawy burmistrza z Autstralii), oraz idiotyzmach i nielogicznościach jego wypowiedzi.
Z zaskoczeniem obserwuję co najmniej trzy postawy w stosunku do Chatu GPT:
- Traktowanie go jako “mądrzejszej wyszukiwarki” Google - część osób reprezentujących ten pogląd uważa, że ChatGPT jest po prostu “językowym opakowaniem” na wyszukiwarkę treści;
- Hurraoptymizm i przekonanie, że mamy do czynienia z “prawdziwym AI”, które zrewolucjonizuje każdy element życia - takie podejście przeważa wśród technologicznych entuzjastów, korporacyjnych managerów i niektórych osób zainteresowanych “AI”.
- Silny sceptycyzm lub wręcz strach przed utratą pracy i zastąpieniem przez nowy wynalazek - takie głosy dochodzą m.in. z grona programistów, obserwujących możliwości Chatu GPT, modelu CODEX, czy Github Copilot-a.
Wiele osób, zupełnie nie zdaje sobie sprawy, czym tak naprawdę jest ChatGPT i pokrewne rozwiązania. Co za tym idzie: dlaczego działają tak, jak działają i dlaczego się mylą. Spróbujmy odpowiedzieć na to pytanie.
Uczenie maszynowe
ChatGPT należy do bardzo szerokiego grona dużych modeli językowych (ang. LLM - large language models), algorytmów uczenia maszynowego (ML - ang. machine learning znanych od dawna i stanowiących jedna z poddziedzin badań nad sztuczną inteligencją. Powstało wiele definicji tego zagadnienia, myślę, że możemy w tym miejscu przytoczyć dwie.
Pierwszą z nich jest określenie terminu “uczenie się”, sformułowane przez Herberta Simona - laureata nagrody Nobla w dziedzinie ekonomii, jednego z pionierów badań nad SI.
Uczenie się oznacza takie zmiany adaptacyjne w systemie, iż jest on w stanie lepiej wykonać w przyszłości takie same zadania lub zadania należące do tej samej kategorii. Simon, H. A. (1983). Why should machines learn?. W Machine learning (pp. 25-37). Morgan Kaufmann. (tł. własne)
Drugą definicją jest ta sformułowana przez wybitnego polskiego naukowca, autora znakomitej książki “Systemy Uczące się”, Pawła Cichosza:
Uczeniem się systemu jest każda autonomiczna zmiana w systemie zachodząca na podstawie doświadczeń, która prowadzi do poprawy jakości jego działania. Cichosz, P. (2007) Systemy uczące się. Wyd. 2. Warszawa: Wydawnictwa Naukowo-Techniczne
W obu tych definicjach widzimy łączące je, ważne punkty:
- Stopniowe nabywanie doświadczenia.
- Wykorzystywanie tego doświadczenia, do stopniowej poprawy działania systemu.
- Autonomiczny charakter zmian - to oznacza, że system sam reguluje sposób wykorzystania zgromadzonej wiedzy i nie wymaga przeprogramowywania przez człowieka.
Tak, w ogromnym skrócie, wygląda działanie większości systemów uczenia maszynowego. Wiele z nich, w tym modele językowe, uczymy w sposób bardzo podobny do tego, jak uczą się ludzie:
- Pokazujemy przykładowe dane (pytania), wraz z odpowiedziami.
- Pozwalamy algorytmowi przedstawić własne odpowiedzi.
- Weryfikujemy wynik z “kluczem” (poprawnymi odpowiedziami), dając sygnał zwrotny: “dobrze/źle”, dzięki czemu system koryguje swoje zachowanie.
Pokazany wyżej proces nosi nazwę “uczenia nadzorowanego” i jest jednym z wielu sposobów szkolenia modeli ML.
Modele językowe
Modele językowe, do których należy ChatGPT, Bard i podobne wpisują się w opisany schemat. W ich przypadku, uczenie polega na pokazywaniu zdań z języka naturalnego, wraz z ich kontekstem i np. kategorią tematyczną, do której należą. Algorytm uczy się, jakie sekwencje słów, zdań, akapitów i paragrafów, opisują dane zagadnienia. Podział na pytania/materiał do nauki i proponowane odpowiedzi może w tym przypadku wyglądać następująco:
| Zadanie | Pytanie | Poprawne odpowiedzi |
|---|---|---|
| Jakie powinno być następne słowo? | Ala ma | kota |
| Bitwa pod Grunwaldem rozegrała się w | 1410 roku | |
| 1410 r. | ||
| AD 1410 | ||
| Do jakiej kategorii należy zdanie? | Na giełdzie zapanowały ponure nastroje, kursy akcji lecą w dół. | Ekonomia |
| Finanse | ||
| Giełda | ||
| Prezydent wygłosił wspaniałe przemówienie, które wzmocni jego pozycję w nadchodzących wyborach. | Polityka | |
| Publicystyka | ||
| … | ||
| Odpowiedz na pytanie pełnym zdaniem. | Ile kół ma typowy samochód? | Typowy samochód ma 4 koła. |
| Samochód ma cztery koła. | ||
| Auta mają po 4 koła. | ||
| … |
Jak widać, wiele pytań/zadań ma więcej niż jedną poprawną odpowiedź. Zazwyczaj można ją sformułować na kilka sposobów, w danym języku. Zdarza się też, że treści mogą być wzajemnie sprzeczne (Ala ma kota, Ala ma bzika, Ala ma fioła).
Co bardzo ważne - ChatGPT i inne modele z jego rodziny uczą się operowania językiem naturalnym przez analizę wielu zdań i wypowiedzi. Tymczasem wiele postów/komentarzy i opinii jest wzajemnie sprzecznych, zwłaszcza gdy Internauci wyrażają w nich swoje opinie. Zadaniem LLM-ów jest formułować wypowiedzi na piśmie, podobnie jak robi to człowiek przy klawiaturze, nie są natomiast encyklopediami ani bazą wiedzy symbolicznej.
Gdy zaglądasz do encyklopedii, szukasz zazwyczaj po indeksie (np. litera “u” → uczenie maszynowe) lub w danej kategorii (np. kategoria nauki ścisłe → litera “u” → uczenie maszynowe).
Modele językowe są uczone na kategoriach zdań, owszem (np. zdania z zakresu polityki lub ekonomii), ale ich zadaniem jest formułowanie płynnych wypowiedzi na dany temat, a nie poszukiwania encyklopedyczne (z małymi wyjątkami, patrz niżej 🙂).
W jaki sposób te modele mogą rozumieć język pisany? Istnieje wiele sposobów szkolenia, ale jednym z nich są tzw. mechanizmy uwagi, stanowiące podwaliny architektury o znajomo brzmiącej nazwie “Transformery”.
Mechanizm uwagi i transformery
Człowiek posługujący się dowolnym językiem, zapoznając się z wypowiedzią, buduje w swojej głowie “drzewo zależności” - co zdanie opisuje, w jakim czasie, co jest podmiotem, a co orzeczeniem. Każdy język rządzi się swoimi prawami, język angielski i pokrewne mają co prawda pod pewnymi względami przewagę (ograniczona odmiana słów w porównaniu np. do języka polskiego), ale zasada działania jest bardzo podobna.
Spójrz na poniższe zdanie:
Kobieta usiadła na ławce i rozglądała się po parku.
Kto usiadł? Kobieta.
Na czym usiadła? Na ławce.
Kto się rozglądał - kobieta, czy ławka? Kobieta.
Dla osoby znającej język polski takie zależności są oczywiste. Obcokrajowcy, oraz systemy językowe jak ChatGPT muszą je poznać. Ludzie uczą się na kursach gramatyki, czasów, stron i trybów, robiąc ćwiczenia i rozmawiając z lektorami.
ChatGPT i modele językowe przerabiają miliony podobnych przykładów, dostając informację zwrotną, czy:
- Prawidłowo rozpoznały kontekst;
- Wygenerowane przez nie wypowiedzi są podobne do używanych w danym języku.
Mechanizm uwagi (ang. attention nazywany też przez mechanizmem atencji pozwala algorytmom brać pod uwagę dotychczasowy kontekst zdania i wpływ poszczególnych jego części na to, co ma być dalej (następne słowo lub zdanie), lub na analizę tematu/zagadnienia (klasyfikacja).
Mechanizmy uwagi w sztucznych sieciach neuronowych pełnią zbliżoną rolę do pól recepcyjnych i “uwagi konkurencyjnej” w organizmach biologicznych - skupiają system na wybranym kawałku otoczenia, pozwalając analizować kontekst zachodzących zdarzeń.
Diagram poniżej pokazuje bardzo uproszczony mechanizm działania uwagi dla przykładowego zdania. Gwiazdki wskazują podmiot zdania: jest nim kobieta i niewątpliwie dalsze elementy zdania będą odnosić się do niej, jako głównej “bohaterki”.
Wiele zagnieżdżonych mechanizmów uwagi, działających wspólnie z dodatkowymi fragmentami sieci składają się na architekturę zwaną “Transformerem”, która pozwala przetwarzać nawet bardzo długie sekwencje.
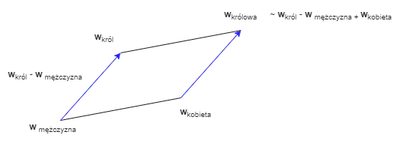
Warto pamiętać też, że algorytmy uczenia maszynowego nie przetwarzają języka bezpośrednio - słowa są zmieniane na reprezentację numeryczną w mechanizmie zwanym “osadzaniem” (ang. embedding) - który pozwala przedstawiać słowa jako wektory liczb. W procesie uczenia następuje szereg operacji probabilistycznych i matematycznych, mających odzwierciedlić uczone treści. Jeśli wszystko idzie zgodnie z planem, pojęcia bliskoznaczne znajdują się wówczas niedaleko siebie na płaszczyźnie numerycznej. Dodatkowo, możliwe są na nich operacje arytmetyczne, prowadzące do zaskakująco trafnych przekształceń jak np:
król - mężczyzna + kobieta ~ królowa
Przykład umiejscowienia słów jako reprezentacji numerycznych znajduje się poniżej:
Jakiś czas temu, miałem przyjemność opowiadać podczas konferencji Data Science Summit o dokładnym mechanizmie wykorzystania osadzeń/embedding’ów w zadaniach klasyfikacji, lub rekomendacji. Materiały z wykładu znajdziesz tutaj
ChatGPT został nauczony na ogromnych zbiorach tekstów z sieci (m. in. BooksCorpus, WebText2) oraz tzw. Common Crawl. Jest to zbiór danych składający się z miliardów stron internetowych, które są regularnie przeszukiwane i indeksowane przez roboty Google i innych podobnych firm. OpenAI, organizacja odpowiedzialna za stworzenie ChatGPT, wykorzystała wersję z 2019 roku tego zbioru, która składała się z ponad 40 terabajtów danych tekstowych. Zbiór zawierał wiele różnych typów tekstów, w tym artykuły, recenzje, wpisy na blogach, a nawet fora internetowe.
Co ważne: wiele tekstów i wypowiedzi krążących w Internecie jest wzajemnie sprzeczna. Ludzie podają nieprawdziwe informacje, odpowiadają nie na temat, tworzą teorie spiskowe…. Wszystko to, wraz z kontekstem wypowiedzi stało się materiałem uczącym dla LLM.
Chodząca encyklopedia?
Powyższy, mocno uproszczony opis, powinien dać nam pewien ogląd czym są i jak działają algorytmy pokrewne do ChatuGPT. W najprostszym ujęciu, są to modele uczenia maszynowego, bazujące na wielu przykładach, jakie im przedstawiono, nauczone generowania nowych wypowiedzi, będących odpowiedziami na konkretne pytania, lub w sposób swobodny.
Swoje teksty konstruują za każdym razem od nowa, kierując się mechanizmami kontekstu i uwagi, pozwalającymi na rozpoznanie tematu “dyskusji”, dotąd wypowiedzianych kwestii itd. W tym procesie starają się upodobnić własne dzieła do tych, które były im przedstawione jako charakterystyczne dla danego języka.
W tym kontekście, ChatGPT i modele LLM nie mogą być uznawane za “chodzące encyklopedie”, albo wyszukiwarki treści. Nie posiadają ustrukturyzowanej wiedzy encyklopedycznej, nie są uwarunkowane na udzielanie “poprawnych odpowiedzi” - generują słowa, które mają być spójne z językiem, w jakim prowadzona jest konwersacja, kontekstem rozmowy, jej tematem, itp. Z tego względu, mogą mijać się z prawdą.
W chwili pisania tego tekstu, powstają już wtyczki i rozszerzenia, pozwalające modelom LLM łączyć się z bazami wiedzy, posługiwać się wyszukiwarkami treści, albo narzędziami matematycznymi takimi jak Wolfram Alpha do wykonywania celowo poprawnych obliczeń lub wyszukiwania encyklpedycznych informacji.
Nie zmienia to jednak faktu, że w swoim jądrze modele LLM są modelami językowymi a nie chodzącymi encyklopediami. Z tego względu “oskarżanie” ich o popełnienie błędu albo generowanie nieprawidłowych treści jest zupełnym niezrozumieniem przeznaczenia tych narzędzi.
Sztuczne języki
Mając na uwadze powyższy opis, można sobie zadać pytanie: dlaczego ChatGPT tak dobrze programuje i pisze kod relatywnie sprawnie?
Słowo “język” w odniesieniu do dialektów programistycznych jest uzasadnione. Języki programowania to symboliczne, sztuczne języki, o charakterze utylitarnym, czyli służącym konkretnemu celowi - tworzeniu działających aplikacji i algorytmów w sposób imperatywny, czyli jednoznacznie wskazujący na operacje do wykonania.
W przeciwieństwie do ludzkich języków, języki programowania:
- są dużo bardziej jednoznaczne, pozbawione zbędnych “ozdobników” ;
- mają ściśle określoną składnię.
- Dodatkowo: kod udostępniony publicznie w Internecie bardzo często jest napisany poprawnie i działa.
Jeśli dodamy do siebie powyższe trzy punkty:
jednoznaczność + czytelny, sformalizowany język + dużo poprawnych i prawidłowych przykładów
otrzymujemy znakomity zestaw wypowiedzi uczących dla LLM. W przeciwieństwie do forów, blogów i komentarzy, gdzie każdy wyraża swoje opinie - “wypowiedzi” pisane w językach programowania są dużo bardziej zwarte, poprawne i jednoznaczne.
Co dalej?
Niewątpliwie ChatGPT i pokrewne modele LLM stanową rewolucję w dziedzinie praktycznych zastosowań AI. Pozwolą na automatyzację wielu zadań, generowanie treści, do tej pory zarezerwowanych dla ludzkich twórców, w tym także kodu źródłowego aplikacji.
Stawia to wiele wyzwań m.in przed systemem edukacji - jak prawidłowo rozpoznawać prace stworzone samodzielnie przez studentów? Jak uchronić ludzi przed popadnięciem w lenistwo i wyręczaniem się LLM w wielu zadaniach, zamiast pobudzać własną kreatywność i wyobraźnię? Jak uniknąć korporacyjnego monopolu firm, mających odpowiednie zaplecze technologiczne do szkolenia modeli LLM, i narzucających swoje rozwiązania innym? Jak rozwiązać prawny problem własności intelektualnej danych, na których uczono model?
Technologia ewoluuje, ale rozwój społeczny nie nadąża za tymi zmianami. Nowe czasy przynoszą nowe narzędzia, które musimy zaakceptować i nauczyć się z nimi funkcjonować. Pewne zawody znikną, pojawią się nowe, wymagające współpracy z narzędziami takimi jak LLM.
Warto jednak zachować zdrowy rozsądek a przede wszystkim zrozumieć, z czym mamy do czynienia.
Jako zawodowy analityk danych i programista nie boję się o pracę w kontekście modeli LLM - bardzo mnie cieszy, że dostaniemy tak przydatne narzędzie. Boję się natomiast reakcji ludzi i sposobu, w jaki będą oni korzystać z LLM-mów: często niezgodnie z przeznaczeniem i ze szkodą dla samych siebie, oraz swoich organizacji, czy instytucji.